Исследователи из Сингапура провели эксперимент с группами детей разного возраста и выяснили, что доверие к машине или человеку зависит от того, сколько лет ребенку и насколько поступающая от обоих информация кажется ему достоверной.
Современные дети каждый день сталкиваются с цифровыми технологиями и искусственным интеллектом. Чтобы отвлечь даже годовалого ребенка в автомобиле, ему дают планшет с мультиками. Поэтому исследования о том, кому больше доверяют дети — машине или человеку, — с каждым годом становится все актуальнее.
Важно здесь и понимание того, насколько в будущем эти дети будут доверять фейковой информации, часть которой уже сегодня нередко генерируется ИИ. По мере взросления способность оценивать достоверность источника информации становится важным навыком для развития критического мышления.
Ученые из Сингапурского университета технологии и дизайна решили больше узнать о том, кому дети доверяют больше — людям или машинам, — и провели эксперимент. Его выводы представлены в журнале Child Development.
В исследовании приняли участие 120 детей из дошкольных учреждений Сингапура в возрасте от трех до пяти лет (57 из них были девочками, чаще всего азиатского происхождения). Их поделили на две группы: в первой (младшей) оказались малыши до 4,5 года, во второй — все остальные. Затем с каждым из детей общался информатор: либо робот-андроид от SoftBank Robotics NAO, обладающий человекоподобным, но роботизированным голосом, либо человек.
Чтобы условия эксперимента можно было сопоставить, люди, общавшиеся с детьми, согласовывали свои действия с действиями робота. Рядом с каждым из участников также сидел экспериментатор, задававший необходимые вопросы, чтобы ребенок не чувствовал давления и не соглашался с информатором, если он того не желает.
Ученые выяснили, что все дети готовы были доверять информации, поступившей как от роботов, так и от людей. Однако это происходило лишь в том случае, если и те, и другие до этого сообщали им точные данные о том или ином предмете (условно: называли мяч мячом, а не пирамидкой). Если же и те, и другие информаторы были ненадежными (ранее путались в своих данных), то дети из младшей группы, несмотря на ошибки обоих, больше доверяли человеку, а не роботу. Ребята постарше не верили обоим: вне зависимости от того, кто перед ними — машина или человек, — они смотрели не на этот критерий, а на то, насколько достоверна, по их мнению, информация, которую предоставляли собеседники.
«При создании роботов и других моделей на основе искусственного интеллекта для образовательных целей разработчики должны учитывать особенности восприятия маленьких детей. Понимание того, как меняется их доверие к людям и машинам по мере взросления, может способствовать созданию более эффективных условий обучения, гарантируя то, что применение технологий соответствует развивающимся когнитивным и социальным потребностям ребенка», — заявил соавтор исследования профессор Куин Йоу (W. Quin Yow).
Почти под каждым постом, который затрагивает вопрос средней зарплаты в уездном городе N, обязательно появится комментарий с подобной шуткой (или любой другой ее вариант — про макароны по-флотски или среднюю температуру по больнице с учетом умерших). Давайте разберемся, почему эта шутка плохая. И дело не только в том, что она не смешная и повторяется вместе с каждой публикацией статистических показателей.
Многие уже поняли, что среднее арифметическое зарплат и его динамика не лучший способ анализа благосостояния граждан уездного города N, и начали требовать медианных значений. Это здравое желание, но, к сожалению, медиана тоже не всегда дает результат, нужный недовольным комментаторам. Как же перестать ненавидеть Росстат и зажравшихся энчан и полюбить статистику?
«Есть три вида лжи: маленькая ложь, большая ложь и статистика»
(2-е место в хит-параде шуток про статистику).
Сами по себе данные не хорошие и не плохие. Вопрос только в том, что мы видим за этими числами. Чтобы лучше понимать, о чем нам хочет сказать очередной пресс-релиз комитета статистики уездного города N, нужно говорить со статистической наукой на одном языке. Конечно, среднее арифметическое — это далеко не все, а лишь одна из характеристик выборки. К сожалению, в школе вся математическая статистика сводится исключительно к нему. Возможно, именно потому, что жители N не знают других терминов, пресс-секретарь статистического ведомства публикует именно эту характеристику (нет, совсем не потому, что мэру нужно отчитаться).
Допустим, сегодня вышел пресс-релиз:
На центральной площади перед ратушей уездного города N провели выборочный опрос и выяснилось, что средний заработок энчан составляет 60 у. е. В паблике «Подслушано N» сразу начались словесные баталии. Появились комментарии о том, что ни у кого из знакомых автора зарплаты больше 30 у. е. нет, а такое значение возможно только потому, что статистическое ведомство лжет или у мэра зарплата в 10 000 у. е. Ну и обязательная шутка про голубцы, куда же без нее.
Кто же лжет в славном городе N: мэр, статистическое ведомство или же кто-то еще?
Чтобы разобраться, начнем с понятия выборки. Правильно сформировать выборку для опроса — особый квест. Очевидно, что если бы мы могли опросить всех горожан, то получили бы информацию о доходах всей популяции. Эта выборка точно была бы репрезентативной. Однако мы можем опросить не всех, а только некоторую часть жителей. И чем меньше людей участвует в опросе, тем ниже репрезентативность данных.
Можно ли считать выборку случайных людей на центральной площади репрезентативной? Однозначного ответа нет. На этот показатель может влиять день недели (будний/выходной), приезд делегации из столичного города M и еще очень много других факторов. В идеале после опроса все демографические соотношения (мужчины/женщины, дети/взрослые/пенсионеры и прочие) должны совпадать с общегородской статистикой — для этого и проводится перепись населения. Если выборка не отвечает этим требованиям, то она нерепрезентативна, а значит, это ошибка и доверять такому отчету нельзя.
Допустим, что выборка была репрезентативной, но данные для большинства горожан всё равно удивительные. Они таких зарплат даже не видят. Чтобы понять, почему среднее арифметическое позволяет довольно точно оценить знания школьников, посчитав средний балл за контрольную, не очень помогает оценить среднюю температуру по больнице и совершенно не работает при оценке доходов населения, нам понадобится понятие дисперсии.
Дисперсия — это мера «разброса» случайной величины от ее самого вероятного значения. У учеников оценка может быть от 2 до 5. Если мы считаем, что наиболее вероятная оценка у школьников 3,5, то мы имеем дисперсию, равную 1,5. Это небольшая дисперсия. Она позволяет нам говорить о том, что среднее арифметическое класса достаточно показательно, если мы хотим сравнить, какой класс знает математику лучше. При помощи такой аргументации гораздо проще объяснить маме тройку, чем доказывать, что у всех вообще два. Согласитесь, «Мама, я сделал вывод, что моя тройка с плюсом выше среднего арифметического в классе, что говорит о том, что я заслуживаю поощрения, а не наказания» звучит гораздо убедительнее, чем «Мама! Да у всех вообще двойки!».
В случае со средней температурой по больнице всё становится интереснее. Дисперсия температуры у живого человека не такая уж большая — от примерно +34 до +42 °С при максимально ожидаемой +36,6 °С. Это позволяет нам говорить, что среднее арифметическое достаточно показательно для оценки ситуации. Можно сказать, что в среднем пациенты в инфекционном отделении теплее пациентов в травматологическом. Однако всё меняется, если добавить труп с комнатной температурой. Это увеличивает дисперсию и приводит к тому, что среднее становится совершенно нерепрезентативным.
Точно так же можно посмотреть на статистику среднего возраста рождения первого/второго/третьего ребенка у женщины. Почему все учитывают именно женщин, а не мужчин? С агрегацией данных по мужчинам возникает много проблем: разная дисперсия по сравнению с женщинами (у женщин период, когда они могут иметь детей, гораздо короче, чем у мужчин), принципиально разное количество детей, которые могут появиться в течение жизни, сложности с достоверным установлением отцовства.
Несколько лет назад одна лаборатория опубликовала статистику, согласно которой около 10 % тестов на отцовство были отрицательными. Человек, который не знаком со статистикой, мог бы предположить, что 10 % детей воспитываются не своими родителями. Это одна из классических ловушек восприятия статистической информации, которая хорошо накладывается на предыдущие выводы по поводу однородности выборки:
«Никогда не переносите данные опроса на всю популяцию, если не убедились в корректности выборки».
В нашем случае отцовство действительно не подтвердилось в 10 % тестов, но что это была за выборка? Это люди, которые уже настолько сомневались в отцовстве, что пошли проверять его в лабораторию.
Перейдем к нашему вопросу с зарплатами. Дисперсия у зарплат может более чем в 10 раз превышать наиболее вероятный доход. Именно из-за этого говорить о среднем арифметическом как о репрезентативном показателе зарплаты гражданина из массы совершенно бессмысленно.
Понять, что происходит с зарплатами в городе N, помогут медиана и мода.
Медиана — это значение, при котором половина измерений будут больше нее, а половина — меньше нее.
Мода — самое часто встречающееся значение.
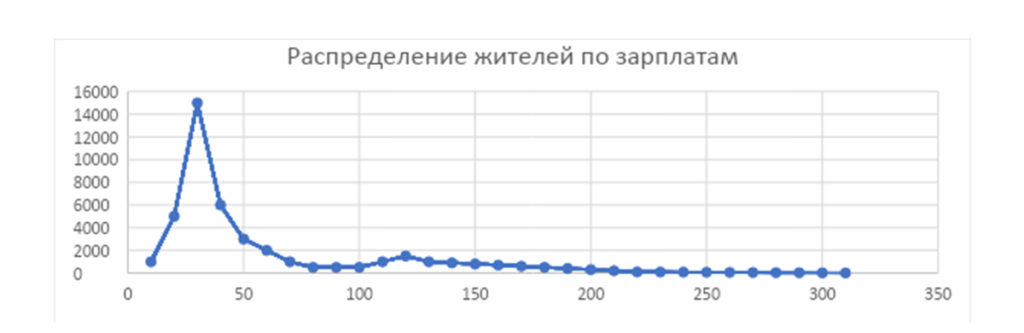
Посмотрим, что насчитал нам статистический орган города N. Пресс-секретарь утверждает, что распределение по полу, возрасту, месту жительства и виду деятельности совпадает с общегородским, то есть опрос репрезентативен.
На горизонтальной оси отображается уровень зарплаты, который указал житель во время опроса, а на вертикальной — количество людей с указанными зарплатами
В нашем городе получились следующие показатели:
Средняя зарплата составила 60 у. е., однако такой зарплатой и выше могут похвастаться только 12 тысяч из 43 тысяч опрошенных, то есть около четверти населения N. Такое неравенство не может не вызывать удивления у жителей, и чем больше будет дисперсия по зарплатам в нашем городе, тем меньше энчане будут доверять значению средней зарплаты.
Посмотрим теперь на моду и медиану.
Медиана составит 40 у. е., а мода — 30 у. е. Мода — высокий пик на графике в 15 тысяч человек, примерно такого результата горожане и ожидают.
В моде практически каждый житель города узнает себя, своего знакомого или, по крайней мере, не удивится такому значению.
В нашем случае мода немного больше, но тоже не вызовет особого возмущения.
Каждая характеристика распределения позволяет что-то понять о распределении, однако даже все вместе они могут подводить. Например, модальное значение может быть совершенно случайным на малых выборках или если мы попробуем спрашивать о зарплате у людей с точностью до копейки. Тогда три человека с абсолютно одинаковой зарплатой могут иметь самое частое значение в выборке.
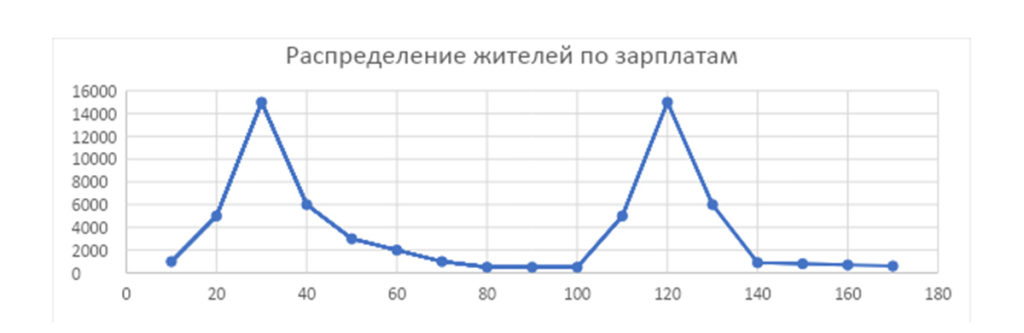
Другая ситуация — если у нас есть два равных пика. Например, в N не одно, а два градообразующих предприятия, причем одно из них в четыре раза успешнее другого. Мы получим вот такое распределение по зарплатам:
Здесь у нас получатся две моды: 30 и 120. Медиана будет 65, а средняя зарплата по городу будет 76. Полноценную картину может дать только общий набор данных.
Где и как мы можем применить эти знания в реальной жизни? Не стоит воспринимать контринтуитивную статистику как заведомый обман, но и доверять ей на все сто не надо. Статистика ради статистики — удел весьма своеобразных людей, вся остальная статистика собирается под конкретные запросы и задачи. Если же всплывают какие-нибудь данные, которые вызывают массовые бугурты, — возможно, эту информацию собирали не для общего пользования. Опять же, любые данные, которые вызвали у вас вопросы, можно проверить на адекватность, размер выборки и сохранение пропорций. Если отнестись к этому с чуть большим уважением и любопытством, можно открыть для себя огромный мир данных, из которых можно получать очень любопытные зависимости и последовательности.
Рассуждения о вреде избытка информации можно найти еще в древнем философском трактате «Экклезиаст», датируемым III в. до н.э. Однако понятие «информационная перегрузка» появилось лишь в 1964 году благодаря политологу Бертраму Гроссу. Позднее американский философ Элвин Тоффлер популяризовал термин, а в первой четверти XXI века ученые заговорили о последствиях информационного изобилия, например, о медиабулимии, распространенном современном недуге. В том, что собой представляет «медиабулимия», к чему приводит неосознанное и неконтролируемое потребление информации и почему нас преследует чувство опустошения и растерянности в новом информационном мире, Моноклер разбирался вместе с исследовательницей, аспиранткой Киевского национального университета имени Т. Шевченко Анной Одинец.
Понятие медиабулимии все еще остается относительно малоизвестным, хотя признаки социальной болезни уже были описаны многими психологами. Анна Одинец обозначила этот термин одной из первых еще четыре года назад.
Мастерская (два персонажа), Пабло Пикассо, 1934
Медиабулимия сравнима с известным пищевым расстройством. Но в данном случае речь идет о неосознанном потреблении всевозможной информации. Происхождение термина опирается на аналогию между пищевым и информационным голодом, для которых характерны отсутствие осознанности при потреблении, зависимость от поглощаемых продуктов и чувство опустошения после очередного «переедания». Как замечает Анна Одинец в одном из научных докладов, «“обжорство” легко доступной информацией приводит к отвращению от нее, затем следует период нехватки и самобичевания за отказ. Подобное чередование способствует развитию депрессивных состояний и психосоматических расстройств».
В разговоре исследовательница добавляет:
Этот процесс сродни поглощению пищи. Если беспрерывно глотать все подряд, ничего не пережевывая, то момент насыщения осознается с опозданием, являя собой качественный перегруз, и как следствие, вызывая резкое отторжение и «возвратный рефлекс». Проблемы со вниманием постепенно обрамляются в синдром дефицита внимания и гиперактивности.
Наиболее сильно данному недугу подвержено молодое поколение, так как именно оно чаще всего проводит время в сети. При этом, согласно данным проекта «EU KIDS ONLINE», в котором исследовались вопросы пребывания молодежи в интернете, распространенное мнение о том, что сетевая компетентность помогает избавиться от информационных угроз и перегрузок, не соответствует действительности. По замечанию кандидата педагогических наук, доцента Г. Михалевой, основной риск связан с социальными сетями, чатами и всплывающими информационными окнами.
Лавина информации не только окружает нас, но и требует взаимодействия. В результате мы не только имеем бесконечное количество источников для самостоятельных исследований любых вопросов, но и регулярные отвлекающие сигналы в виде рекламных, деловых, личных уведомлений и спама. В результате мы можем говорить о неконтролируемости информационного потока.
Некоторых тешит иллюзия о том, что доступность информации делает нас более развитыми. Однако на практике все обстоит ровно наоборот: обилие источников не говорит об их достоверности, и в итоге мы находимся в эпохе тотальной дезинформации. Кроме того, исследования показали, что, чем больше вариантов источников знаний мы имеем, тем сложнее нам ориентироваться и делать выбор в окружающем мире. Таким образом, мы можем говорить о времени, в котором над нами довлеют растерянность и отсутствие концентрации.
Психологи, социологи и философы на протяжении нескольких лет предупреждают о «побочных действиях» постоянного пребывания в сети, в особенности в рабочее и учебное время, а также во время отпуска. Регулярная, ежеминутная смена информационных образов, зачастую с противоположным друг другу содержанием, будь то тексты, видео или изображения, делают нас растерянными, раздражительными и депрессивными. Пытаясь угнаться за духом времени, мы перестаем вчитываться в тексты, рефлексировать, и в итоге оказываемся лишены возможности радоваться пониманию прочитанного, а позднее и вовсе способности глубоко анализировать то или иное явление. Также привычка «читать по диагонали», свойственная многим пользователям, стремящимся охватить как можно большее количество информации, ведет к утере культуры чтения как таковой, что неизбежно делает нас более конформными, ведомыми и программируемыми, так как мы привыкаем откликаться на простые и известные нам онлайн-сигналы. Поверхностное скольжение и постоянное открытие все новых и новых вкладок, по данным А. Одинец, является одним из симптомов медийной булимии.
Феномен заключается в том, что зачастую, даже понимая абсурдность сложившейся ситуации, многие не могут перестать потреблять ненужную им информацию. Анна Одинец замечает:
Знание – сила, информация дает власть, поэтому кажется, что чем большим количеством информации мы обладаем, тем сильнее, значимее мы становимся. Вопрос о нужности или качестве получаемого – отходит на второй план ... Невозможно предугадать, что окажется в хайпе в следующую неделю, поэтому, на всякий случай, поглощается все подряд. Социальные сети, вроде Twitter – только ухудшают ситуацию. Пост друга о том, что он хочет фруктовый салат на ужин никак не повлияет на мою жизнь лично, но страх пропустить что-то важное подстегивает пользователей просматривать огромную кучу бесполезной информации в поисках чего-то хоть сколько-нибудь ценного.
Чувство опустошения, деградации, невозможности сосредоточиться или сделать конкретный выбор приводит к нервным срывам, отчаянию, депрессивным состояниям и временному отказу от сети. Однако после все повторяется заново, практически по той же схеме, что и при пищевой зависимости: пользователи потребляют все подряд без разбора, чувствуют вину за потраченное зря время, но одновременно являются зависимыми от сетевого контента и неизбежно возвращаются к статусу «онлайн».
По мнению доцента кафедры социальной философии и философии истории СПбГУ С. К. Секацкого, мир стал переполнен «сорной визуальностью». При этом доктор философских наук, профессор СПбГУ В.В. Савчук замечает, что данная реальность порождает феномен «несмотрения», который «является своеобразным способом самосохранения здоровья».
Относительно того, какие меры способны помочь избежать медиабулимии, эксперт поясняет:
Стоит выработать такой себе «ментальный иммунитет», который будет заключаться в критическом мышлении.
Нужно задавать себе вопросы: Стоит ли мне это читать/смотреть? Есть ли мне на самом деле до этого дело?
А вот перестать быть зависимым от информации у нас никак не получится. Все живые существа зависимы от разной информации, и человек в первую очередь. Вопрос только в количестве, которое нужно регулировать самостоятельно.
Блогер Крис Бейли объясняет, что контент, который мы потребляем, влияет на нашу личность и на то, как складывается наша жизнь.
Качество и содержание информации, которую мы потребляем, имеет значение. Это влияет практически на все аспекты нашей личности, в том числе:
о чем мы думаем,
как мы думаем,
на что обращаем внимание в окружающем нас мире,
что мы замечаем,
качество наших решений,
насколько разумно мы работаем,
богатство нашей личной жизни,
сколько идей мы придумали,
насколько мы учитываем других людей в своих действиях и решениях.
Словом, когда речь идет о том, что мы потребляем, практично не всегда значит интересно.
Чтобы проиллюстрировать это, можно разделить информацию на несколько типов, которые имеют разные уровни полезности и развлекательной ценности:
Полезная информация обычно крайне важна, но не очень интересна. Например, книги, журнальные статьи, онлайн-курсы и академические беседы. Информация в этой категории имеет практическое применение, точна и обычно остается актуальной в течение длительного времени.
Сбалансированная информация немного менее полезна, но более интересна, поэтому ее легче потреблять. Например, документальные фильмы, выступления на TED и популярные книги по психологии.
И, наконец, третья группа — как развлекательная, так и низкопробная информация, — это развлекательный контент, который совсем чуть-чуть полезен (и очень интересен), а также разный информационный мусор, который мы часто употребляем в больших дозах. Например, много видео на YouTube, некоторые подкасты, любовные романы, ночные ток-шоу и ленты социальных сетей.
Абсолютно все, что мы потребляем, попадает в одну из этих категорий. К полезной информации обычно стоит обращаться, когда у вас много энергии, сбалансированная информация отлично подходит для тех случаев, когда энергии поменьше, но все еще хочется чувствовать, что вы к чему-то стремитесь, а развлекательная информация подходит, когда вам хочется просто потупить. Вероятно, стоит потреблять поменьше низкопробной информации — к тому же есть гораздо лучшие способы восполнения энергии.
Итак, что можно сделать с этим знанием? В эпизоде моего подкаста «Becoming Better» на этой неделе я разбирался, какую информацию люди потребляют каждый день, а также в значении и удовольствии, которое она приносит. Очень важно знать, чему вы отдаете большую часть своего времени, а также стремиться получать более ценную информацию.
Есть бесчисленное множество способов сделать это. Например:
Постарайтесь дать цену своему вниманию. Просмотрите описание аудиокниг, подкастов и телешоу. Стоят ли они того времени и внимания, которое вы собираетесь уделить им?
Подумайте о ценных вещах, которые вы можете внести в свою жизнь. Какой навык вы еще не развивали? Какая тема вас всегда интересовала? Может быть, стоит узнать кое-что об этом вместо очередного пролистывания ленты социальных сетей?
Обратите внимание, какой контент вы потребляете в режиме автопилота, не задумываясь. Обычно так происходит с наименее ценной информацией.
Получайте ту информацию, которая вам близка. Например, я люблю читать журнальные статьи о производительности. Хотя, по общему признанию, это странное увлечение, я считаю, что в этом мое преимущество — эти статьи интересны не многим. Возьмите за правило опираться на знания и навыки, которые важны для вас.
Тупите намеренно.
Вы станете роботом, если будете потреблять только полезную информацию. Чтобы получить больше удовольствия от безделья — ну, когда в следующий раз засядете смотреть свои любимые сериалы на Netflix, — делайте это намеренно. Спланируйте, сколько серий вы посмотрите, что вы будете есть во время просмотра, кого пригласите составить вам компанию, и так далее. Вы не просто лучше проведете время, но также будете чувствовать себя менее виноватыми по этому поводу.
Не существует двух одинаковых единиц информации. Мы воспринимаем мир через информацию, которую получили в прошлом — это одна из множества причин, по которым состояние внимания определяет структуру жизни. Все вышеперечисленные стратегии — отличные способы лучше провести время, одновременно повышая качество своего внимания.
Показ рекламы - единственный способ получения дохода проектом EmoSurf.
Наш сайт не перегружен рекламными блоками (у нас их отрисовывается всего 2 в мобильной версии и 3 в настольной).
Мы очень Вас просим внести наш сайт в белый список вашего блокировщика рекламы, это позволит проекту существовать дальше и дарить вам интересный, познавательный и развлекательный контент!
































 Смех
Смех Вдохновение
Вдохновение Радость
Радость Интерес
Интерес Удивление
Удивление Красота
Красота Умиление
Умиление Трогательно
Трогательно Гнев
Гнев Отвращение
Отвращение