В истории науки есть редкие личности, чьё значение заметно далеко за пределами академических аудиторий. Джон фон Нейман — именно такой человек. Он стоял у истоков теории игр, архитектуры компьютеров, квантовой механики и даже атомной физики. То, что он придумал — стало частью нашей повседневной жизни: компьютеры, стратегии, которые мы используем, и экономические модели, основанные на его открытиях, — всё это явилось результатом его работы.
Многие считают Джона фон Неймана „последним полиматом“ — человеком, чьё мышление охватывало всё: от основ компьютеров до стратегий поведения и атомных технологий. Эта статья — попытка понять, как он успел настолько многое дать миру.
Пролог: Человек, который видел будущее в формулах
В архивах Института перспективных исследований в Принстоне хранится странная записка, написанная рукой Джона фон Неймана в 1954 году: «Машины научатся думать раньше, чем мы поймем, как думаем сами». Под этими словами - математическое уравнение, описывающее рост интеллекта как функцию от времени. Кривая устремляется в бесконечность около 2045 года.
Глава I: Алхимик памяти
Мало кто знает, что фон Нейман страдал от странной формы гипертимезии - он помнил абсолютно всё. Не просто факты или числа, а каждый разговор, каждую страницу каждой прочитан-ной книги, каждый запах и звук. Его память работала как без-граничная библиотека с мгновенным доступом к любому «файлу».
Коллега-математик Станислав Улам рассказывал: «Джонни мог процитировать дословно любую страницу из "Упадка и разрушения Римской империи" Гиббона - всех шести томов. Но самое поразительное: он мог делать это задом наперёд, начиная с последнего предложения».
Эта сверхпамять была не даром, а проклятием. Фон Нейман видел связи там, где другие видели хаос. Он помнил каждую обиду, каждое разочарование с пугающей ясностью. Возможно, поэтому он так стремился создать машины, которые могли бы забывать - и тем самым стать более человечными, чем он сам.
Глава II: Венгерский заговор
В Будапеште начала XX века существовала удивительная концентрация будущих гениев: фон Нейман, Лео Силард, Эдвард Теллер, Юджин Вигнер. Все они вышли из одного социального круга, посещали одни и те же салоны, говорили на одном языке интеллектуальной элиты.
Их называли «марсианами» - не только из-за венгерского акцента, но и из-за их сверхъестественных способностей. Физик Энрико Ферми однажды заметил: «Они не могут быть людьми. Они слишком умны».
Но за этой легендой скрывается более глубокая история. Венгерская еврейская интеллигенция того времени жила на краю исчезновения. Они знали, что их мир обречён, и поэтому вкладывали всю свою энергию в создание знания, которое переживёт их. Фон Нейман не просто изучал математику - он создавал интеллектуальный ковчег для человеческого разума.
Глава III: Тайна игры в покер
Мало кто связывает теорию игр фон Неймана с его страстью к покеру в лос-аламосских казино. Но именно за покерными столами он понял фундаментальную истину о человеческой природе: мы не рациональные существа, мы - существа, пытающиеся казаться рациональными.
Его «Теория игр и экономическое поведение», написанная совместно с Оскаром Моргенштерном, была не просто математическим трактатом. Это была попытка создать математику человеческой души - систему уравнений, способную предсказать, как поведут себя люди в ситуации неопределённости.
Фон Нейман заметил, что лучшие покеристы играют не против карт, а против других игроков. Они создают модели сознания оппонентов и постоянно их обновляют. Именно эта идея - машины, моделирующей другие сознания - стала основой для его работы над искусственным интеллектом.
Глава IV: Анатомия взрыва
Роль фон Неймана в создании атомной бомбы общеизвест-на. Но мало кто знает о его одержимости эстетикой разруше-ния. Он изучал взрывы не только как физический процесс, но и как форму математической поэзии.
В своих записках он описывал ядерный взрыв как «симфо-нию превращений»: материя становится энергией, порядок - хаосом, будущее - прошлым. Он видел в атомной бомбе не оружие, а метафору самой жизни - концентрированную креа-тивность, способную создавать и уничтожать одновременно.
Странно, но именно работа над бомбой привела его к пони-манию живых систем. Он заметил, что и ядерная реакция, и биологическое размножение следуют одному принципу: информация (уран-235 или ДНК) при определённых условиях начинает копировать сама себя в геометрической прогрессии.
Глава V: Машина, мечтающая о бессмертии
Самый амбициозный и малоизвестный проект фон Неймана - попытка создать «цифрового двойника» человеческого сознания. В начале 1950-х он тайно работал над программой, которую называл «Психологическим автоматом».
Идея была революционной: записать все нейронные связи человеческого мозга в виде математических уравнений, а затем воспроизвести их в электронной машине. Фон Нейман мечтал о том, что смерть станет просто переходом от биологического к цифровому существованию.
Он экспериментировал на себе, ведя детальные записи сво-их мыслительных процессов, реакций, ассоциаций. В его архи-вах находят тысячи страниц самонаблюдений - попытку карто-графировать собственное сознание.
Проект провалился не из-за технических ограничений, а из-за философского открытия: фон Нейман понял, что сознание - это не программа, а процесс. Нельзя скопировать реку, можно лишь создать новую реку, похожую на старую.
Глава VI: Пророчество сингулярности
Термин «сингулярность» фон Нейман позаимствовал не из физики, а из литературы. В его библиотеке сохранилась книга Данте с пометками на полях: «Singularitas — точка, где все законы перестают действовать».
Его предсказание о технологической сингулярности роди-лось не из абстрактных рассуждений, а из глубоко личного опыта. Фон Нейман осознал, что его собственный интеллект растёт экспоненциально - каждое новое знание открывает доступ к ещё большему знанию. Он экстраполировал эту закономерность на технологическое развитие.
В частных беседах он говорил: «Я чувствую, как мой разум расширяется каждый день. Но что происходит, когда этот процесс станет доступен машинам? Когда они смогут улучшать сами себя без ограничений биологии?»
Эпилог: Последнее уравнение
В больничной палате, за несколько дней до смерти, фон Нейман попросил принести ему доску. Дрожащей рукой он написал последнее уравнение - формулу, описывающую вероятность выживания человеческой цивилизации в зависимости от скорости технологического развития.
Результат оказался пугающим: чем быстрее мы развиваемся, тем меньше у нас шансов. Не потому, что технологии опасны сами по себе, а потому, что мы не успеваем адаптироваться к созданному нами же миру.
Фон Нейман не оставил нам инструкций по спасению. Он оставил нам вопрос, на который мы до сих пор ищем ответ: как остаться людьми в мире, который становится нечеловеческим?
Его гений заключался не в том, что он знал будущее, а в том, что он понимал: будущее - это не место, куда мы идём, а процесс, который мы создаём. И ответственность за этот процесс лежит на каждом из нас.
В архивах Принстона до сих пор хранятся нераскрытые записи фон Неймана. Быть может, среди них есть ответы на вопросы, которые мы ещё не научились задавать...
Пересказать анекдот? Дурацкая затея. Объяснить шутку? Еще хуже. Научиться шутить? Безнадежно. Посмотрим на юмор с точки зрения ученых и попытаемся выяснить, почему одни люди остроумнее других.
XVI век «Мона Лиза», она же «Джоконда», кисти Леонардо да Винчи — то ли чему-то тихо улыбается, то ли нет Источник: Alamy / Legion-media
Взгляд математика: генерация случайных слов
Немца Артура Шопенгауэра прозвали философом пессимизма: он считал, что наш мир — худший из миров. Шопенгауэр жил в одиночестве (с пуделем), избегал людей, периодически нанимал корреспондентов для поиска подтверждений своей известности и, как ни странно, при этом кое-что понимал в природе юмора. Во всяком случае, первая статья, описывающая юмор в математических терминах («On the quantification of humor as entropy» в Journal of Memory and Language), цитирует именно его идеи о комическом эффекте разрыва реальности и ожиданий.
Исследование канадских и немецких ученых под руководством профессора психологии Криса Уэстбери было опубликовано в конце 2015 года. В предыдущих опытах ученые предлагали больным с нарушениями речи различать выдуманные и настоящие слова. Тогда исследователи заметили, что некоторые нереальные слова кажутся людям гораздо смешнее остальных. Нужно было выяснить почему и еще научиться заранее определять, какие слова окажутся самыми забавными.
Для этого ученые сгенерировали несколько тысяч новых несуществующих слов и дали оценить уже здоровым испытуемым по шкале смеха от 1 (совсем не смешно) до 7 (очень смешно). Наивысшие баллы набрали слова, отдаленно напоминающие пошлости и ругательства. Эти результаты заметно превосходили остальные, поэтому ученые выкинули подобные двусмысленные комбинации букв из рассмотрения и сконцентрировались на приличных и бессмысленных словах вроде yuzz-a-ma-tuzz.
Самыми смешными оказались слова с наименьшей информационной энтропией: проще говоря, такие комбинации букв, которые меньше всего напоминают настоящие слова. Увидев их, мозг словно пытался разгадать загадку (понять, какое важное сообщение несет столь необычный набор символов) и, изрядно помучившись, выдавал ответ: полная бессмыслица и никаких аналогий с реальностью, остается только посмеяться — это, мол, было интересно.
Ян Стен. «Урок танцев». XVII век Источник: piemags via Legion Media
Во второй серии экспериментов ученые еще больше убедились в верности гипотезы: чем меньше смысла, тем смешнее. Они брали пару слов, считали их энтропию с помощью базы всех слов английского языка и по разнице результатов предсказывали, какое слово покажется испытуемым более смешным. С вероятностью до 90% математический метод верно предсказывал реакцию живых людей. Итак, на 90% смешное — это неожиданное.
Взгляд социолога: свой среди своих
«Парень версия 5.0» и «девушка версия 3.4» любили друг друга. Однажды они сделали апгрейд до «мужа 1.0» и «жены 1.0», но что-то пошло не так. В новых версиях программ нашлись баги: «муж 1.0» удалил «романтику 9.5», «жена 1.0» установила мониторы на все его процессы, а потом программы и вовсе стали неожиданно выдавать детей.
Все версии этого длинного анекдота (выше мы привели его в сокращенном виде) на девяти самых популярных языках собирала по Интернету Лаймор Шифман, израильский профессор в области коммуникации. Она изучала, как шутка меняется в разных культурах. Выяснилось: японцы больше подтрунивали над женами, корейцы — над мужьями, в страстных португальских версиях вылезли пикантные подробности программ, а в целомудренных китайских — вирусы «тещи». В немецкой версии американские виды спорта и ассоциации (вроде NBA — баскетбол) менялись на местные (вроде Bundesliga). В арабской версии не было никаких отсылок к добрачным отношениям. Интересно, что ближе всего к английскому оригиналу оказалась португальская версия, а на втором месте русская (французская на четвертом).
XVII век «Смеющийся скрипач», нидерландский художник Геррит ван Хонтхорст. Ок. 1623 Источник: Bridgeman / Fotodom.ru
Юмор помогает понять повседневную жизнь и найти в ней сторонников. Человек в 30 раз реже смеется в одиночестве, чем на людях: вряд ли кому-то придет в голову рассказывать анекдоты перед зеркалом. Все остроумие мы бережем для других, потому что юмор — способ прощупать социальную почву, понять, кто здесь свой, а кто чужой. Смеешься над шутками про Штирлица, тещу и Вовочку — наш человек и вообще хороший парень. С глупой улыбкой отсиживаешься в темном углу — с таким в разведку не пойдешь.
Именно поэтому мужчины чаще приглашают на второе свидание девушек, смеющихся над их шутками («есть у нас что-то общее, я сразу почувствовал»), школьники так любят пересказывать друг другу свежий ролик на YouTube, хотя накануне каждый пересмотрел его раз по десять.
Кстати, Лаймор Шифман провела еще одно исследование. Она собрала 100 самых популярных англоязычных анекдотов и посмотрела, как они расползлись в Интернете по другим странам и языкам. Французы потеряли буквально несколько из них, арабы — гораздо больше, а китайцы — уже почти все. Чем сильнее разница в культуре и языке, тем меньше общих анекдотов.
Взгляд биолога: ультразвуковой смех
Разные люди смеются над разными вещами. Американские психологи под руководством Яака Панксеппа доказали, что звери тоже умеют смеяться. В середине 1980-х годов они изучали крысиные игры. Ученые последовательно блокировали грызунам разные органы чувств и смотрели, как это будет влиять на их веселую возню. Самый яркий эффект дало отсутствие слуха: глухие крысята перестали прыгать друг другу на спину и весело копошиться в клетках. Игры прекратились.
Оказалось, что крысы предупреждают сородичей о добрых намерениях писком на частоте 50 кГц, своеобразным ультразвуковым смехом. Такие радостные звуки в предвкушении еды они издают на месте кормежки, так добродушно приветствуют друг друга старые особи и так же, смехом, юнцы говорят друг другу: «Не бойся. Это странно, что я прыгнул тебе на спину, но я просто играю. Веселюсь».
XVIII век «Лиотар смеющийся» — автопортрет швейцарского живописца Жан-Этьена Лиотара. Ок. 1770 Источник: Bridgeman / Fotodom.ru
У человека подобную функцию выполняет улыбка. Она как будто говорит: «Я впервые тебя вижу, я говорю странные вещи, на моей странице в соцсети такая крупная фотография, словно я подошел слишком близко к тебе, но я улыбаюсь и потому совсем не опасен».
Юмор и смех — это средство сообщить другим о своих странных и необъяснимых, но не опасных открытиях. А также возможность преодолеть страх. Неслучайно в анекдотах так много секса, насилия и болезней. Люди хотят найти общие пределы дозволенного, перейти их на словах и с улыбкой, чтобы в жизни даже не приближаться к границе предельного опыта.
Взгляд физиолога: дофаминовая зависимость
Так что же происходит в нашей голове, когда нам смешно? Американский нейрофизиолог Скотт Уимз исследовал анатомию юмора с помощью МРТ-сканера. Он помещал в сканер людей, включал им смешные мультфильмы и фиксировал реакцию мозга. У испытуемых увеличивалась активность в зонах, отвечающих за дофаминовый цикл вознаграждения (дофамин — один из главных нейромедиаторов, веществ, регулирующих работу головного мозга; его часто называют гормоном счастья).
Похожие эффекты, согласно другим исследованиям, вызывают кокаин, шоколад и видеоигры. Человек как будто подсажен природой на смех и юмор: кто раз от души посмеялся, тот будет стремиться к смеху и дальше.
Начало XX века «Девушка в большой шляпе», Роберт Генри (один из основоположников современного искусства США) Источник: Bridgeman / Fotodom.ru
Юмор создает зависимость. При этом некоторые зависимости дают и положительный эффект. Например, видеоигры могут способствовать обучению, а шоколад вызывает быстрое повышение сахара в крови, что бывает полезным и даже необходимым в определенных ситуациях.
А в чем польза смеха? Ведь вместо шуточек и глупого веселья можно с серьезным видом заниматься самообразованием, уходом за садом или даже покорением мира (Гитлер, например, не любил и не понимал шуток). В романе Умберто Эко «Имя розы» хранитель монастырской библиотеки убивал всех людей, которые пытались добраться до потерянного трактата Аристотеля о комедии: «Иисус никогда не смеялся». Доказать мрачному монаху необходимость смеха коллегам так и не удалось.
Эту необходимость выявили исследования других нейрофизиологов (см. The Science of When We Laugh and Why, 2014). Оказывается, мозг работает с юмором, как с интеллектуальной загадкой, головоломкой. «Когда я дошел до самого дна, снизу постучали»: дно → падение → изгой → стук → помощь = поддержка → новый друг. Озарение: «Там снизу есть люк, чтобы выбраться, и вообще это неправда, что ты куда-то падаешь!» — кричит нам мозг (это интерпретация автора; в редакции «Вокруг света» данный анекдот трактуется более трагически). Смейтесь, жизнь будет легче!
XX век Портрет Майкла Джексона, Энди Уорхол. 1984 Источник: Bridgeman / Fotodom.ru
Юмор — неуловимое умение совмещать несовместимое и различать скрытые смыслы там, где другие видят только черное и белое. Может, именно поэтому нам подсознательно нравятся остроумные и тонкие люди? Они быстро придут на помощь: сумеют найти выход из любой ситуации. Даже люк на дне моря или бассейна обнаружат.
Порой кажется, что растения растут беспорядочно, в случайной последовательности. Но правда в том, что окончания каждой ветки, листа, стебля, почки или лепестка согласуются с определенными законами. Куда ни глянь, в природе есть шаблоны и образцы, самым постоянным из которых является последовательность Фибоначчи.
Впервые числа Фибоначчи описали древнеиндийские математики за сотни лет до нашей эры, хоть они и названы в честь итальянского математика Леонардо из Пизы, более известного как Фибоначчи.
Последовательность Фибоначчи проста до невозможности: каждое последующее число является суммой двух предыдущих, т. е. последовательность выглядит как 1, 1, 2, 3, 5, 8, 13, 21… и так далее до бесконечности. Кстати, числа Фибоначчи можно найти в природе практически где угодно. К примеру, расположение листьев вдоль стебля подпадает под последовательность Фибоначчи, так что каждый лист имеет максимальный доступ к солнечному свету и влаге. По такому же принципу работает строение сосновых шишек, подсолнухов, ананасов и кактусов.
Возможно, вы слышали о таком явлении, как золотое сечение, — это и есть еще одна форма последовательности Фибоначчи в природе. И все растения так или иначе имеют свою геометрию. Однако у одних из них геометрия более очевидная и яркая, чем у других. И вот лишь некоторые примеры.
Романеско
Романеско отличается светло-зеленым цветом и незабываемым видом, по своей форме напоминая фрактал. По сравнению с обычной цветной капустой текстура романеско как овоща не такая хрустящая, а вкус не такой характерный, скорее утонченный и ореховый.
Толстянка «Буддистский храм»
Это гибрид между толстянками видов Crassula falcata и Crassula pyramidalis, выведенный в 1959 году Мироном Кимнахом из США. Но так как этот представитель флоры очень медленно растет, его никогда широко не рекламировали. Так что даже спустя 50 лет после создания «Буддистский храм» все еще трудно найти. Растение достигает почти 15 см в высоту и начинает раскрываться на разных уровнях по бокам от каждой колонны. Плоские тонкие листья серебристо-серого или серовато-зеленого оттенка плотно идут друг за другом и завернуты вверх по краям, образуя идеально квадратную колонну.
Aloe polyphylla
Алоэ вида polyphylla растет высоко на травянистых склонах Драконовых гор в Королевстве Лесото, недалеко от ЮАР. Здесь оно цепляется за скалистые трещины и хорошо просушенные склоны. В этой местности довольно прохладный климат летом, а зимой алоэ часто покрывает глубоким снегом. Из-за своей симметричной спиральной формы это растение стало объектом вожделения коллекционеров, однако его трудно культивировать, и обычно оно погибает, если забрать его с «родины». В Южной Африке покупка или коллекционирование этого растения является преступлением.
Георгина
Георгина — обычный садовый цветок, но присматривались ли вы к нему? Существует 42 вида георгины, и их листья могут достигать от 5 до 30 см.
Подсолнух
Семенная шапка подсолнуха следует спирали Ферма, которая основана на последовательности Фибоначчи.
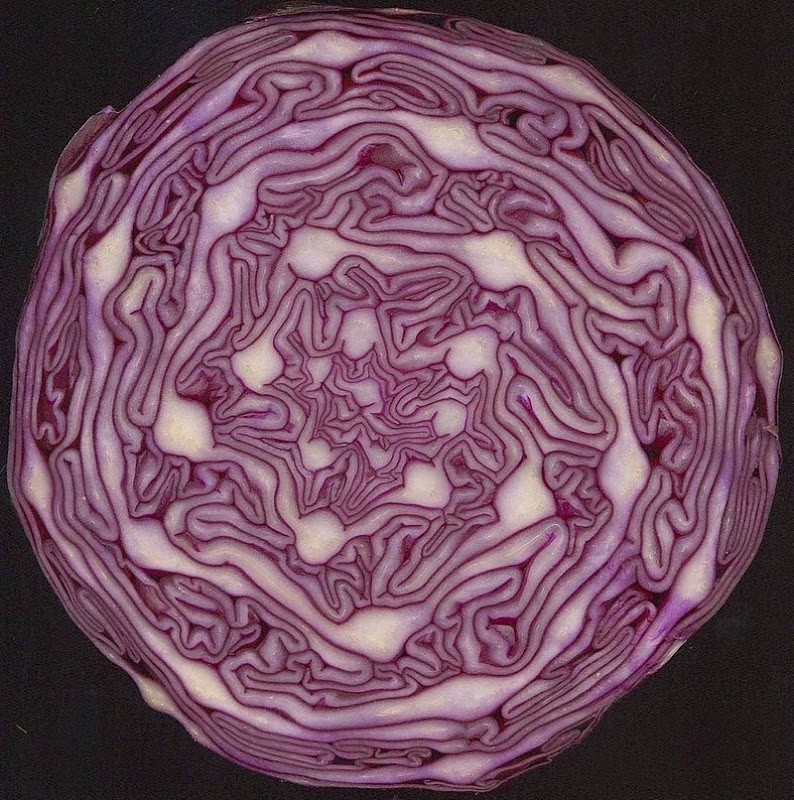
Капуста краснокочанная
Если разрезать краснокочанную капусту пополам по горизонтали, вы увидите спирали Фибоначчи в расположении листьев.
Пелецифора мокрицевидная
Пелецифора мокрицевидная имеет серо-зеленый цвет и круглую форму с плосковатыми узелками, которые отличаются чешуйчатыми позвонками и расположены в форме спирали. Она может вырастать до 10 см в высоту, а ее цветки ярко-фиолетового цвета достигают ширины 3 см. Это растение относительно редкое, и его можно найти только в Северной Мексике.
Ludwigia sedioides
Ludwigia sedioides, известный также как Мозаичный цветок, — это многолетнее травянистое растение, которое произрастает только на болотах Бразилии и Венесуэлы.
Lobelia deckenii
Lobelia deckenii — это вид лобелии гигантской, который растет в горах Восточной Африки. Обычно это растение дает многочисленные розетты. Обычно они соединены под землей. Каждая розетта растет несколько десятилетий, дает одно крупное соцветие и сотни тысяч семян, а затем погибает.
Дудник
Цветочная головка дудника имеет круглую форму. Каждая ее часть похожа на целую головку тем, что имеет стебель и собственный круг цветков. Дудник — это род, к которому относится около 60 видов высоких двухлетних и многолетних растений семейства зонтичных. Он произрастает в умеренных и субполярных регионах Северного полушария, достигая даже Исландии и Лапландии. Вырастает до 1-3 м высотой, имеет крупные двуперистые листья и большие сложные зонтики белых или зеленовато-белых цветков.
Виктория амазонская, она же виктория регия.
Это родственник обыкновенной кувшинки, который, как понятно из названия, в диком виде встречается в Южной Америке, в реках с медленным течением или тамошних заводях. Её сразу можно отличить от других видов благодаря огромным листьям до двух метров диаметром. Листья эти усилены снизу полыми рёбрами и могут выдержать вес в 30-50 кг, если груз расположить точно в центре листа. Снизу эта красота покрыта острыми и длинными шипами для защиты от рыб и прочих животных, а по краям листья имеют щели, через которые вытекает вода, скопившаяся на верхней стороне. Джозеф Пакстон, садовник герцога Девонширского, использовал принцип жилкования листа этого растения при проектировании дворца «Кристал Пэлас» в Лондоне и был первым, кто смог вывезти эту кувшинку за пределы родины и создать условия для цветения.
Почти под каждым постом, который затрагивает вопрос средней зарплаты в уездном городе N, обязательно появится комментарий с подобной шуткой (или любой другой ее вариант — про макароны по-флотски или среднюю температуру по больнице с учетом умерших). Давайте разберемся, почему эта шутка плохая. И дело не только в том, что она не смешная и повторяется вместе с каждой публикацией статистических показателей.
Многие уже поняли, что среднее арифметическое зарплат и его динамика не лучший способ анализа благосостояния граждан уездного города N, и начали требовать медианных значений. Это здравое желание, но, к сожалению, медиана тоже не всегда дает результат, нужный недовольным комментаторам. Как же перестать ненавидеть Росстат и зажравшихся энчан и полюбить статистику?
«Есть три вида лжи: маленькая ложь, большая ложь и статистика»
(2-е место в хит-параде шуток про статистику).
Сами по себе данные не хорошие и не плохие. Вопрос только в том, что мы видим за этими числами. Чтобы лучше понимать, о чем нам хочет сказать очередной пресс-релиз комитета статистики уездного города N, нужно говорить со статистической наукой на одном языке. Конечно, среднее арифметическое — это далеко не все, а лишь одна из характеристик выборки. К сожалению, в школе вся математическая статистика сводится исключительно к нему. Возможно, именно потому, что жители N не знают других терминов, пресс-секретарь статистического ведомства публикует именно эту характеристику (нет, совсем не потому, что мэру нужно отчитаться).
Допустим, сегодня вышел пресс-релиз:
На центральной площади перед ратушей уездного города N провели выборочный опрос и выяснилось, что средний заработок энчан составляет 60 у. е. В паблике «Подслушано N» сразу начались словесные баталии. Появились комментарии о том, что ни у кого из знакомых автора зарплаты больше 30 у. е. нет, а такое значение возможно только потому, что статистическое ведомство лжет или у мэра зарплата в 10 000 у. е. Ну и обязательная шутка про голубцы, куда же без нее.
Кто же лжет в славном городе N: мэр, статистическое ведомство или же кто-то еще?
Чтобы разобраться, начнем с понятия выборки. Правильно сформировать выборку для опроса — особый квест. Очевидно, что если бы мы могли опросить всех горожан, то получили бы информацию о доходах всей популяции. Эта выборка точно была бы репрезентативной. Однако мы можем опросить не всех, а только некоторую часть жителей. И чем меньше людей участвует в опросе, тем ниже репрезентативность данных.
Можно ли считать выборку случайных людей на центральной площади репрезентативной? Однозначного ответа нет. На этот показатель может влиять день недели (будний/выходной), приезд делегации из столичного города M и еще очень много других факторов. В идеале после опроса все демографические соотношения (мужчины/женщины, дети/взрослые/пенсионеры и прочие) должны совпадать с общегородской статистикой — для этого и проводится перепись населения. Если выборка не отвечает этим требованиям, то она нерепрезентативна, а значит, это ошибка и доверять такому отчету нельзя.
Допустим, что выборка была репрезентативной, но данные для большинства горожан всё равно удивительные. Они таких зарплат даже не видят. Чтобы понять, почему среднее арифметическое позволяет довольно точно оценить знания школьников, посчитав средний балл за контрольную, не очень помогает оценить среднюю температуру по больнице и совершенно не работает при оценке доходов населения, нам понадобится понятие дисперсии.
Дисперсия — это мера «разброса» случайной величины от ее самого вероятного значения. У учеников оценка может быть от 2 до 5. Если мы считаем, что наиболее вероятная оценка у школьников 3,5, то мы имеем дисперсию, равную 1,5. Это небольшая дисперсия. Она позволяет нам говорить о том, что среднее арифметическое класса достаточно показательно, если мы хотим сравнить, какой класс знает математику лучше. При помощи такой аргументации гораздо проще объяснить маме тройку, чем доказывать, что у всех вообще два. Согласитесь, «Мама, я сделал вывод, что моя тройка с плюсом выше среднего арифметического в классе, что говорит о том, что я заслуживаю поощрения, а не наказания» звучит гораздо убедительнее, чем «Мама! Да у всех вообще двойки!».
В случае со средней температурой по больнице всё становится интереснее. Дисперсия температуры у живого человека не такая уж большая — от примерно +34 до +42 °С при максимально ожидаемой +36,6 °С. Это позволяет нам говорить, что среднее арифметическое достаточно показательно для оценки ситуации. Можно сказать, что в среднем пациенты в инфекционном отделении теплее пациентов в травматологическом. Однако всё меняется, если добавить труп с комнатной температурой. Это увеличивает дисперсию и приводит к тому, что среднее становится совершенно нерепрезентативным.
Точно так же можно посмотреть на статистику среднего возраста рождения первого/второго/третьего ребенка у женщины. Почему все учитывают именно женщин, а не мужчин? С агрегацией данных по мужчинам возникает много проблем: разная дисперсия по сравнению с женщинами (у женщин период, когда они могут иметь детей, гораздо короче, чем у мужчин), принципиально разное количество детей, которые могут появиться в течение жизни, сложности с достоверным установлением отцовства.
Несколько лет назад одна лаборатория опубликовала статистику, согласно которой около 10 % тестов на отцовство были отрицательными. Человек, который не знаком со статистикой, мог бы предположить, что 10 % детей воспитываются не своими родителями. Это одна из классических ловушек восприятия статистической информации, которая хорошо накладывается на предыдущие выводы по поводу однородности выборки:
«Никогда не переносите данные опроса на всю популяцию, если не убедились в корректности выборки».
В нашем случае отцовство действительно не подтвердилось в 10 % тестов, но что это была за выборка? Это люди, которые уже настолько сомневались в отцовстве, что пошли проверять его в лабораторию.
Перейдем к нашему вопросу с зарплатами. Дисперсия у зарплат может более чем в 10 раз превышать наиболее вероятный доход. Именно из-за этого говорить о среднем арифметическом как о репрезентативном показателе зарплаты гражданина из массы совершенно бессмысленно.
Понять, что происходит с зарплатами в городе N, помогут медиана и мода.
Медиана — это значение, при котором половина измерений будут больше нее, а половина — меньше нее.
Мода — самое часто встречающееся значение.
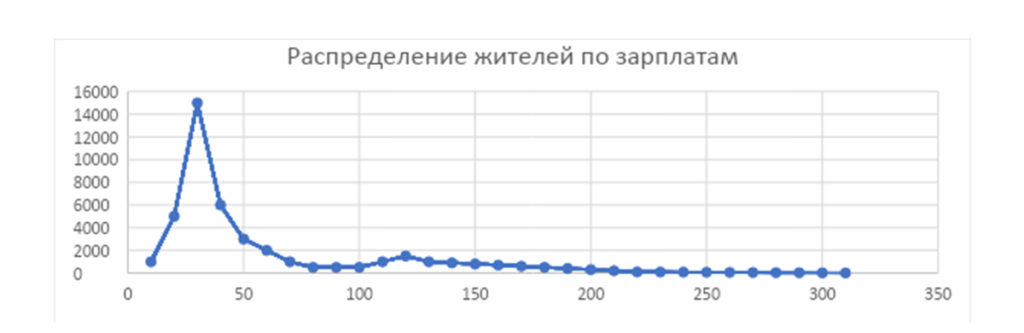
Посмотрим, что насчитал нам статистический орган города N. Пресс-секретарь утверждает, что распределение по полу, возрасту, месту жительства и виду деятельности совпадает с общегородским, то есть опрос репрезентативен.
На горизонтальной оси отображается уровень зарплаты, который указал житель во время опроса, а на вертикальной — количество людей с указанными зарплатами
В нашем городе получились следующие показатели:
Средняя зарплата составила 60 у. е., однако такой зарплатой и выше могут похвастаться только 12 тысяч из 43 тысяч опрошенных, то есть около четверти населения N. Такое неравенство не может не вызывать удивления у жителей, и чем больше будет дисперсия по зарплатам в нашем городе, тем меньше энчане будут доверять значению средней зарплаты.
Посмотрим теперь на моду и медиану.
Медиана составит 40 у. е., а мода — 30 у. е. Мода — высокий пик на графике в 15 тысяч человек, примерно такого результата горожане и ожидают.
В моде практически каждый житель города узнает себя, своего знакомого или, по крайней мере, не удивится такому значению.
В нашем случае мода немного больше, но тоже не вызовет особого возмущения.
Каждая характеристика распределения позволяет что-то понять о распределении, однако даже все вместе они могут подводить. Например, модальное значение может быть совершенно случайным на малых выборках или если мы попробуем спрашивать о зарплате у людей с точностью до копейки. Тогда три человека с абсолютно одинаковой зарплатой могут иметь самое частое значение в выборке.
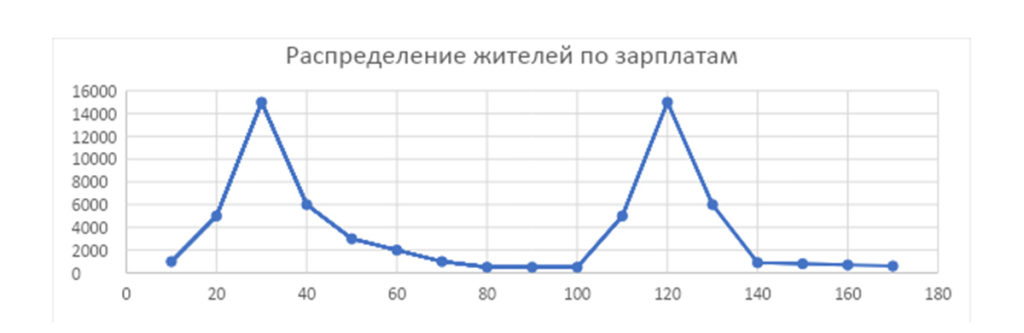
Другая ситуация — если у нас есть два равных пика. Например, в N не одно, а два градообразующих предприятия, причем одно из них в четыре раза успешнее другого. Мы получим вот такое распределение по зарплатам:
Здесь у нас получатся две моды: 30 и 120. Медиана будет 65, а средняя зарплата по городу будет 76. Полноценную картину может дать только общий набор данных.
Где и как мы можем применить эти знания в реальной жизни? Не стоит воспринимать контринтуитивную статистику как заведомый обман, но и доверять ей на все сто не надо. Статистика ради статистики — удел весьма своеобразных людей, вся остальная статистика собирается под конкретные запросы и задачи. Если же всплывают какие-нибудь данные, которые вызывают массовые бугурты, — возможно, эту информацию собирали не для общего пользования. Опять же, любые данные, которые вызвали у вас вопросы, можно проверить на адекватность, размер выборки и сохранение пропорций. Если отнестись к этому с чуть большим уважением и любопытством, можно открыть для себя огромный мир данных, из которых можно получать очень любопытные зависимости и последовательности.
Числа Фибоначчи названы в честь Леонардо Фибоначчи из города Пизы (современная Италия). На самом деле эти числа были известны задолго до Фибоначчи ещё в древней Индии, где они использовались в метрическом стихосложении.
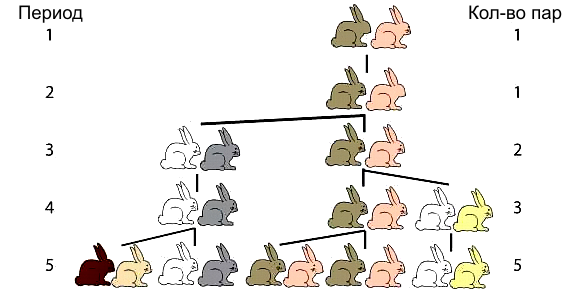
Леонардо Фибоначчи первым ввёл эту числовую последовательность в западноевропейской математической науке в своей важной книге «Liber Abaci» («Книга абака») в 1202 году. Он использовал эту последовательность чисел, когда пытался объяснить рост популяции кроликов.
Фибоначчи рассматривает гипотетическую ситуацию, когда в поле появляется пара кроликов. Они спариваются в конце месяца и в конце второго месяца самка производит еще одну пару. Кролики никогда не умирают, спариваются ровно через месяц, и самки всегда производят пару (один самец, одна самка). Вопрос, который поставил Фибоначчи был следующим: сколько пар будет через один год? Если посчитать, то окажется, что количество пар в конце N-го месяца равно Fn или N-му числу Фибоначчи. Таким образом, количество пар кроликов через 12 месяцев будет F12 или 144.
Числа Фибоначчи и золотое сечение
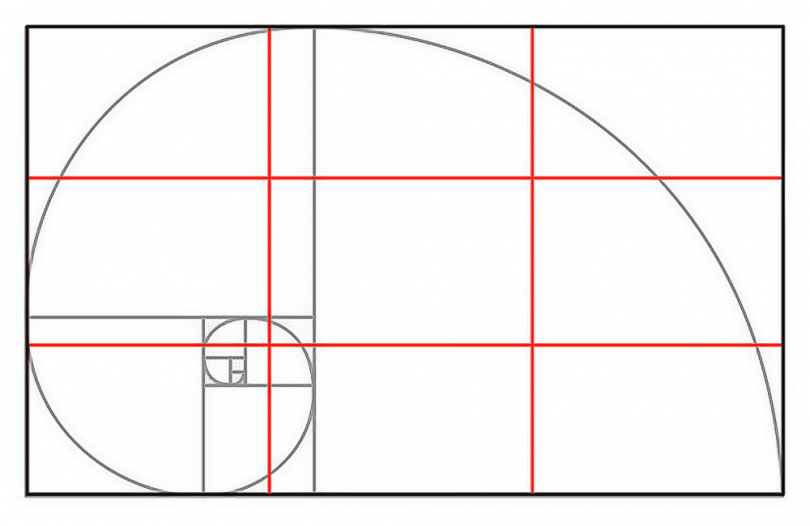
Как известно, последовательность Фибоначчи начинается с 1 и 1, после чего каждое новое число является результатом сложения двух предыдущих чисел:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
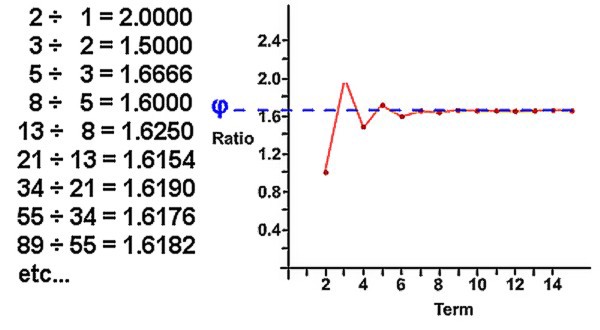
Если разделить два последовательных числа в этом ряду, например 144/89, в конечном итоге получится число 1,618, которое называется «Золотое число» или «Золотое сечение».
Фибоначчи повсюду!
Последовательное приближение соотношения двух соседних чисел ряда Фибоначчи к Золотому сечению.
Пропорция золотого сечения считается эстетически приятной и из-за этого многие художники и архитекторы, в том числе Сальвадор Дали и Ле Корбюзье использовали её в своих работах.
Последовательность Фибоначчи и Золотое сечение тесно взаимосвязаны. Отношение последовательных чисел Фибоначчи сходится и приближается к золотому сечению, а выражение замкнутой формулы для последовательности Фибоначчи включает Золотое сечение.
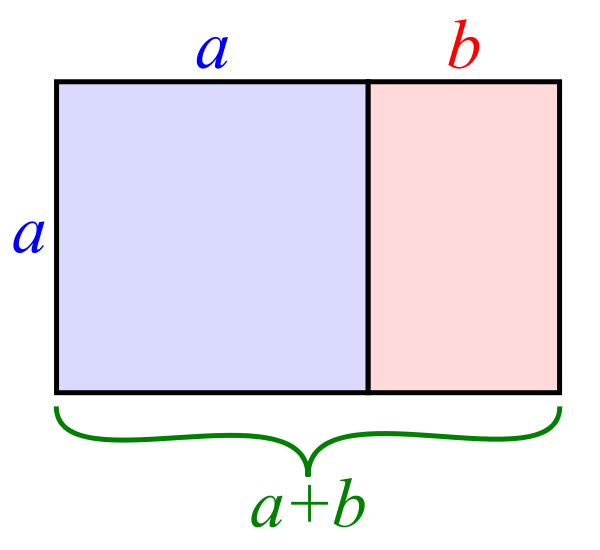
Золотой прямоугольник (розовый) с длинной стороной a и короткой стороной b, и находящийся рядом с ним квадрат со стороной длиной a, создадут подобный золотой прямоугольник с длинной стороной а + b и короткой стороной a. Это изображение иллюстрирует взаимосвязь отношений (a+b)/a = a/b.
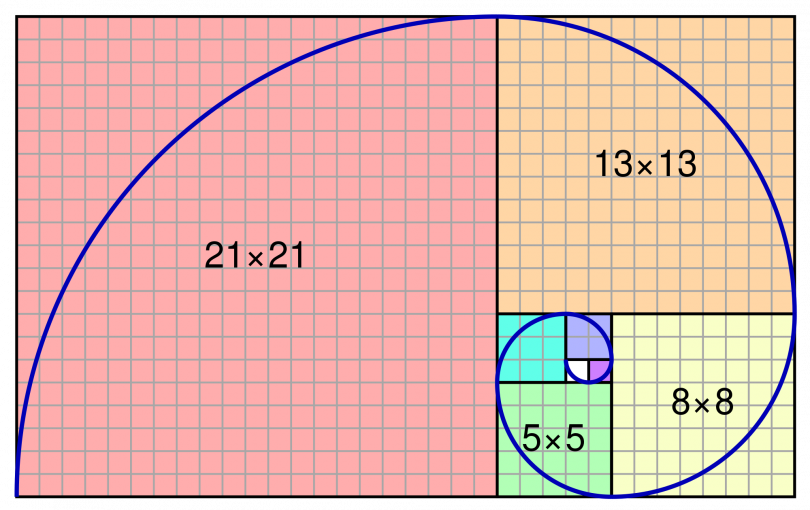
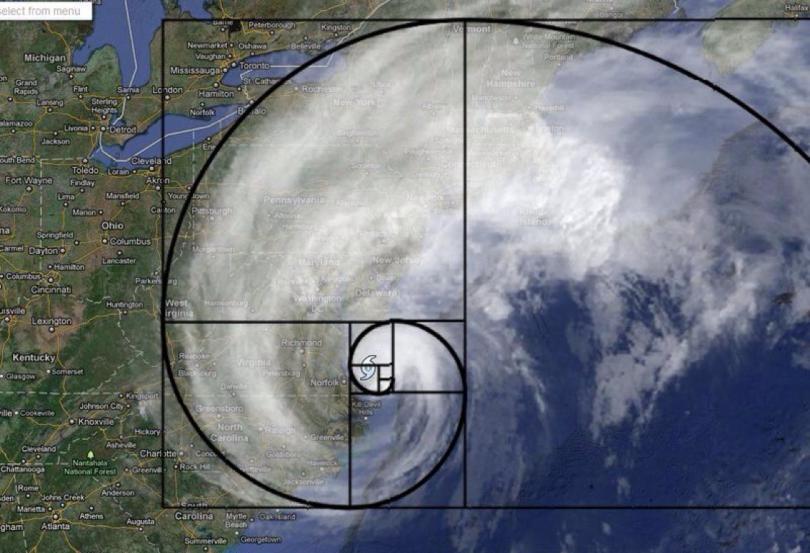
Спираль Фибоначчи или золотая спираль — это последовательность соединенных четвертей окружностей, вписанных внутри массивов квадратов со сторонами равными числам Фибоначчи. Квадраты идеально подходят друг к другу из-за природы последовательности Фибоначчи, в которой следующее число равно сумме двух перед ним (см.предыдущий рисунок). Любые два последовательных числа Фибоначчи имеют отношение, очень близкое к золотому сечению, которое составляет примерно 1.618034. Чем больше пара чисел Фибоначчи, тем ближе это приближение. Спираль и результирующий прямоугольник называются золотым прямоугольником.
Почему эта последовательность настолько уникальна
Числа Фибоначчи описывают различные явления в искусстве, музыке и природе. Числа спиралей на большинстве шишек и ананасах равны числам Фибоначчи. Расположение листьев и ветвей на стеблях многих растений соответствуют числам Фибоначчи. На пианино количество белых (8) клавиш и черных (5) клавиш в каждой октаве (13) являются числами Фибоначчи. Длины и ширины многих прямоугольных предметов, таких как учетные карточки, окна, игральные карты и пр. соответствуют последовательным числам ряда Фибоначчи.
Числа Фибоначчи в природе
Подсолнухи являются отличными примерами последовательности Фибоначчи, потому что семена в центре цветка организованы в два набора спиралей — короткие, идущие по часовой стрелке от центра, и более длинные — против часовой стрелки. Если считать спирали последовательно, то, видимо, всегда найдутся числа Фибоначчи.
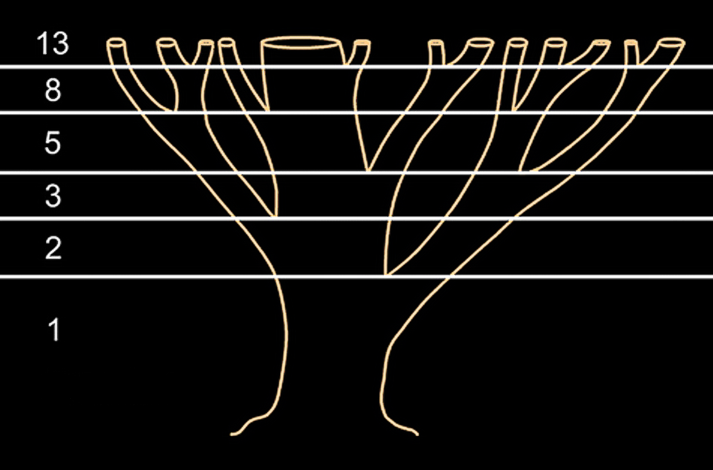
Последовательность Фибоначчи можно также увидеть в форме или разделении ветвей дерева. Основной ствол будет расти до тех пор, пока он не создаст ветвь, которая создает две точки роста. Затем один из новых стеблей разветвляется на два, в то время как другой находится в состоянии покоя. Такая картина ветвления повторяется для каждого из новых стеблей. Корневая система и даже водоросли также демонстрируют эту закономерность.
Вот еще несколько примеров, где вы можете найти спираль Фибоначчи в природе.
Неудивительно, что спиральные галактики также следуют знакомой схеме Фибоначчи. Млечный Путь имеет несколько спиральных рукавов, каждый из которых представляет логарифмическую спираль около 12 градусов.
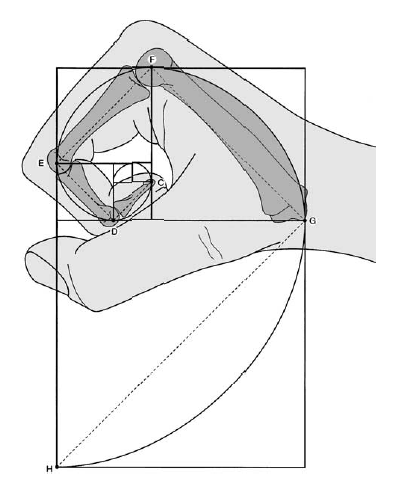
Числа Фибоначчи в теле человека
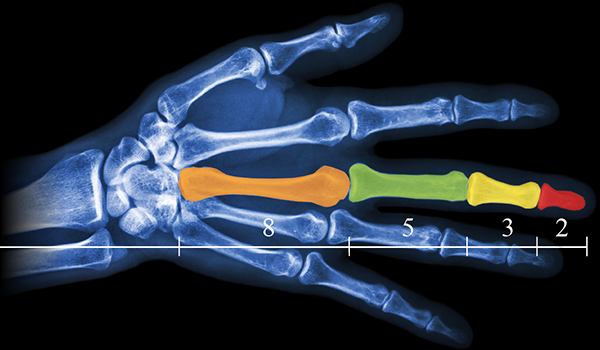
Есть много примеров соотношений частей тела человека на основе последовательности Фибоначчи, например рука и, в частности, кости пальца.
Каждая кость указательного пальца, от кончика до основания запястья, больше предыдущей примерно на коэффициент Фибоначчи 1,618, что соответствует числам Фибоначчи 2, 3, 5 и 8.
Числа Фибоначчи в биржевой торговле
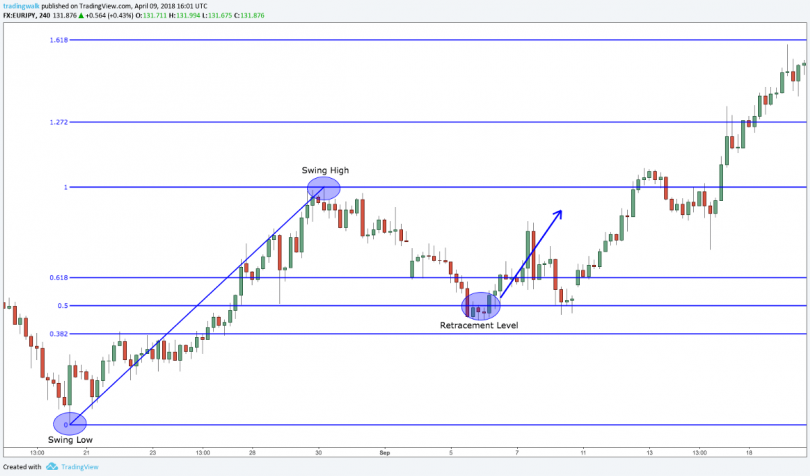
Последовательность Фибоначчи является инструментом технического анализа, используемым профессиональными трейдерами в сочетании с другими инструментами для расчета прогноза потенциального конца коррекции, принимая процент от предыдущего движения.
Считается, что во время мощного рыночного движения, цены могут откатываться на 23,6% (это соответствует отношению числа ряда Фибоначчи на позиции N к числу на позиции N+3), 38,2% (соответствует отношению числа ряда Фибоначчи на позиции N к числу на позиции N+2) или 50% (половина). Эти уровни коррекции Фибоначчи считаются «нормальными». Если же цена падает на 61,2% (отношение двух соседних чисел ряда Фибоначчи — позиции N и N+1) и более, то это серьезный сигнал вероятного разворота тренда.
Числа Фибоначчи в фотографии и искусстве
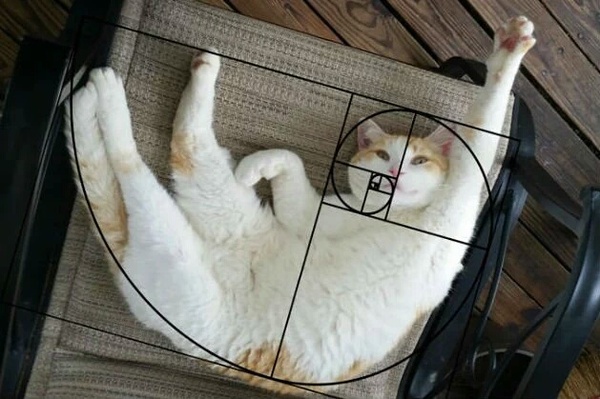
В фотографии сетка фи (phi) является интерполяцией спирали Фибоначчи и в наши дни считается фундаментальным методом для создания приятной композиции в кадре. Цель состоит в том, чтобы выровнять объект по линиям, созданным спиралью, или использовать её в качестве разделителя для создания правильного ощущения кадра.
Сетка фи (красные линии) и спираль Фиббоначи в кадре.
Имеется много примеров, когда последовательность Фибоначчи появляется вокруг нас, и мы не обращаем внимания на это математическое чудо, которое кажется таинственным фактором, приносящим универсальную форму гармонии элементам математического музыкального искусства природы.
Мотивирующая притча, основанная на реальных событиях!
В 1939 году 25-летний математик Джордж Данциг учился в Калифорнийском университете. Однажды он на 20 минут опоздал на пару по статистике. Тихонько вошел, сел за парту и завертел головой, пытаясь понять, что пропустил.
На доске были записаны условия двух задач.
«Ага», подумал Данциг, «ясно — это, видимо, домашнее задание к следующей паре». Студент переписал задачи в тетрадь и стал слушать профессора. Дома он трижды пожалел о том, что опоздал на пару. Задачи были действительно сложными. Данциг думал, что, вероятно, пропустил что-то важное для их решения. Однако делать было нечего. Через несколько дней напряженной работы он все же решил эти задачи. Довольный заскочил к профессору и отдал тетрадь.
Профессор — его звали Ежи Нейман, если кому интересно — рассеянно принял задание. Да, мол, хорошо. Он как-то не смог сразу вспомнить, что не задавал студентам ничего подобного…
Когда спустя некоторое время он таки просмотрел то, что принес ему ученик, у него просто глаза на лоб полезли. Он вспомнил, что действительно в начале одной из лекций рассказывал студентам условия двух этих задач.
Двух теорем, которые на тот момент ещё не были доказаны!
Однако Данциг просто прослушал ту часть лекции, в котором говорилось о сложности этих задач. И решил их.
Иногда вы можете сделать невозможное. Если только не убедите себя сами в том, что это невозможное — невозможно.
Показ рекламы - единственный способ получения дохода проектом EmoSurf.
Наш сайт не перегружен рекламными блоками (у нас их отрисовывается всего 2 в мобильной версии и 3 в настольной).
Мы очень Вас просим внести наш сайт в белый список вашего блокировщика рекламы, это позволит проекту существовать дальше и дарить вам интересный, познавательный и развлекательный контент!

























































 Смех
Смех Вдохновение
Вдохновение Радость
Радость Интерес
Интерес Удивление
Удивление Красота
Красота Умиление
Умиление Трогательно
Трогательно Гнев
Гнев Отвращение
Отвращение